So, you're on the hunt for the best scrapy alternatives? You've landed in the right spot. Diving into web scraping can feel like run through a maze blindfolded. But don't worry because we're here to make your journey smoother.
In this article, you'll learn about the best Scrapy alternatives that range from the straightforward task of HTML parsing to effortlessly navigating the complexities of dynamic web content. You'll also learn what features to look for in a Scrapy alternative.
What is Scrapy and Why Are People Looking For Alternatives?
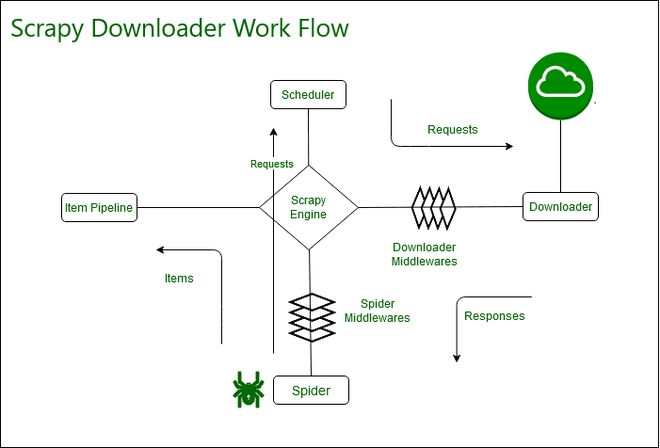
Scrapy is an open-source web crawling framework, designed for data mining, monitoring, and automated testing. It's a powerful tool that allows developers to extract the data they need from websites in a fast, simple way.
Python 3 support was added in Scrapy 1.1. Scrapy lets its user write the rules to extract the data and everything that follows get worked on by the program. It is extensible by design as users can easily plug new functionality without having to touch the core. Scrapy is written in Python and runs on Linux, Windows, Mac and BSD which makes it compatible with different systems.
-Predictive Analytics Today
However, as versatile as Scrapy might be, it doesn't fit every project's needs or skill levels. Some of the most common reasons why people are on the hunt for alternatives include:
The Learning Curve
One of the main reasons people look for alternatives to Scrapy is its steep learning curve. While highly effective once mastered, getting comfortable with Scrapy can take considerable time and effort—especially for those not already familiar with Python or web scraping concepts.
Limited Visual Capabilities
An area where Scrapy shows limitations is in handling JavaScript-heavy sites or extracting data from pages that require interaction (like filling out forms). Since it primarily works by parsing HTML content directly from URLs you provide, it does not render JavaScript like a browser would.
Seeking Simpler Solutions
Sometimes projects don’t require the depth of features offered by Scrapy; this makes simpler tools more appealing due to their ease of use and faster setup times. Many are on the lookout for solutions that offer visual interfaces or direct integration capabilities without writing extensive code.
How The Right Fit For Your Projects
Different projects have unique challenges—be it speed requirements, scale size, or complexity of tasks—that may make other tools more suitable than Scrapy. There’s also consideration for ongoing support and community activity around alternative tools which can significantly impact decision-making.
Considering these elements that push users to explore alternatives beyond Scrapy, the landscape of web scraping technologies is in constant evolution. This advancement provides fresh ways to efficiently extract data from the web, allowing for customized strategies based on the unique needs of each project.
Given the vast array of choices available today, each offering unique features, it's understandable why someone might decide against using Scrapy. The decision ultimately hinges on finding a tool that best meets your immediate and future needs while also considering factors like user-friendliness and efficiency among other important criteria for making well-informed decisions in this field.
What Features Should You Look For in a Scrapy Alternative
When seeking an alternative to Scrapy, a powerful and flexible web scraping framework, it's essential to consider features that align with your project's specific needs, ranging from ease of use to advanced data extraction capabilities.
Scrapy is known for its high efficiency, detailed documentation, and versatility, but depending on your requirements, you might be looking for a tool with different strengths or a more straightforward setup. Here's several key features to look for in an alternative web scraping tool:
1. Ease of Use
For beginners or those preferring quicker setups, look for tools with a user-friendly interface, clear documentation, and strong community support. Tools that offer visual interfaces or simplified coding requirements can significantly reduce the learning curve.
2. Data Extraction Capabilities
The tool should be capable of extracting data from complex web pages, including those that use JavaScript, AJAX, and dynamic content. This might require built-in browser emulation or integration with headless browsers like Puppeteer or Selenium.
3. Data Handling and Storage
Efficient handling of the scraped data is crucial. Look for tools that can easily export data in various formats (CSV, JSON, XML) or directly to databases. It should also support data cleaning and transformation to save time on post-processing.
4. Customization and Extensibility
The ability to customize requests, headers, and the scraping logic itself is important for dealing with complex scraping tasks. Extensibility through plugins or additional modules can also enhance functionality.
5. Compliance and Ethics
Features that help with compliance to legal standards and ethical guidelines, including respecting robots.txt and providing options for identifying the scraper to website administrators, are important considerations.
6. Cross-Platform Support
Consider whether the tool is compatible with various operating systems (Windows, Linux, macOS) if your team or project requires flexibility in the development environment.
The 7 Best Scrapy Alternatives for 2025
As we shimmy our way through 2025, the landscape of web scraping tools is changing. In their quest for superior web scraping solutions, developers tirelessly search for alternatives to Scrapy that enhance adaptability, simplify operations, and boost the effectiveness of contemporary data harvesting practices. Let's take a look at the best Scrapy alternatives for 2025:
1. Beautiful Soup
If you're new to the world of web scraping or simply prefer a tool that makes parsing HTML and XML documents a breeze, Beautiful Soup stands out as an ideal choice. Known for its user-friendly approach, this library simplifies extracting data from web pages by turning complex HTML documents into a tree structure that's easy to navigate.
For those who pair it with the Requests library, web scraping with Beautiful Soup and Requests becomes even simpler. By melding these tools, developers can effortlessly retrieve online material and smoothly transition that data into Beautiful Soup for thorough examination.
The key stat here is its renowned ease-of-use when dealing with both HTML and XML files – making data extraction tasks less daunting especially for beginners in Python web scraping projects.
User Jon says in a G2 review:
The new built-in libraries for processing lxml and html templates make this more of a one-stop shop. It handles a range of text encodings and -- my favourite feature -- the ability to dump ascii text by default. For example, I don't have to worry that my code will crash - instead I just use the get_text() routine that covers the upgradeabilitiy of my software.
2. Magical

With Magical you can scrape information off any site simply and without any code. It uses AI to detect different elements on the webpage you want to scrape-automatically. Just point and click at the information you want to scrape. Then choose where you want that information to go.
User Alan says in a G2 review:
It saves me time and I use it every day. I have to type keywords every day and they usually come in sets. But I can type one keyword with Magical and have all the related keywords automatically added. It also reduces the likelihood of mistakes from typos.
3. Selenium
In scenarios where dynamic content poses challenges beyond what static parsers like Beautiful Soup can handle, Selenium steps up as a robust alternative. This open-source suite doesn't just scrape; it automates entire browsers allowing you to interact with JavaScript-heavy sites much like a human would do.
This capability isn’t limited by browser type or language barriers either since Selenium supports multiple languages and browser automation, making it incredibly versatile not only for large-scale data harvesting but also in areas such as automated testing across different environments including cloud setups.
The ability to mimic real-user interactions helps capture dynamically loaded information which otherwise might be missed by traditional HTTP request-based scrapers.
User Vibhash says on G2:
First of all it is open-source project that provide single interface to write scripts in so many programming language like python, java, perl, ruby, C# etc.
Second thing, it is open-source so anyone can contribute in it from all over the world.
It is used for automation testing for high-end application.
4. Crawlee
A newer player yet equally formidable competitor within our roundup comes Crawlee—touted mainly among JavaScript enthusiasts but not without reason. It offers built-in support ranging from headless browsing (thanks primarily due to Chromium-powered Puppeteer) through traditional GET/POST requests thus covering broad spectrum use cases efficiently whether they require rendering JS code first before fetching needed info.
Rounding off features list includes options designed specifically around resilience strategies such as proxy rotation, captcha solving, etc., all while maintaining high performance standards expected in today’s demanding online spaces.
User Mattias shares on ProductHunt:
Compared to competing libraries, Crawlee is easier to use, yet also more feature rich. In just like 20 lines of code, you can have a crawler set up and ready to go that uses proxy rotation, automatic session management, header generation, fingerprint generation, and request management. When building a crawler with Crawlee, you have more time to focus on the job at hand rather than reinventing the wheel and creating custom implementations for proxy-management or request-management etc.
5. ZenRows
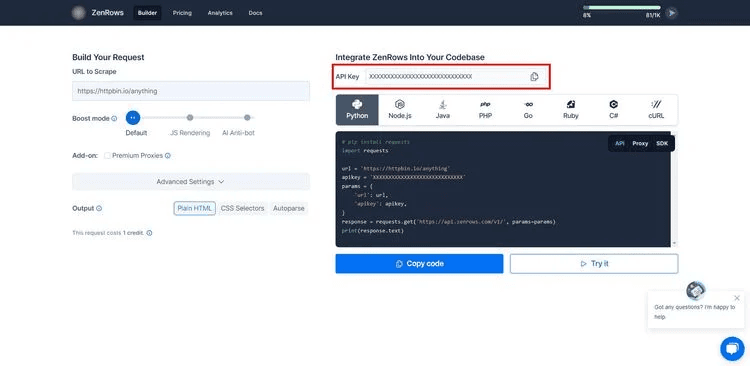
ZenRows is a web scraping API designed to simplify the process of extracting data from websites, particularly those that employ techniques to deter scraping activities, like AJAX calls, JavaScript rendering, and anti-bot measures. As an alternative to Scrapy, which is a more complex and feature-rich framework requiring a certain level of programming knowledge, ZenRows offers a set of features aimed at making web scraping more accessible and efficient, especially for users who prefer a ready-to-use solution over building and maintaining their own scraping infrastructure.
ZenRows offers a level of resilience against changes in website structures. While not immune to all changes, its rendering capabilities and pattern detection can adapt to certain modifications, reducing the need for frequent scraper updates.
As user Mariam says on G2:
What I like the most about ZenRows is the great documentation and the support team, which quickly resolves any issues. It offers reliable scraping and high availability. All this makes ZenRows a must-have for web scraping.
6. Apify
Apify is a cloud-based platform that offers a comprehensive suite of web scraping and automation tools, positioning itself as a versatile alternative to Scrapy. While Scrapy is an open-source framework requiring a more hands-on approach for web scraping projects, Apify provides a more accessible solution with its ready-to-use actors, task automation capabilities, and managed infrastructure.
While Apify and some alternatives offers tools for non-developers, it also provides a flexible platform for coders. Users can write their own actors using JavaScript (Node.js), offering the ability to create custom and complex scraping and automation solutions.
As user Nataniel says on G2:
Apify did a great job at building a user-friendly platform for web scraping and automation, allowing non-tech users to scrape and integrate multiple services. Developers can built their own solutions and easily publish on Apify store, which has over 1000 actors already. The support is pretty good for both users and developers.
7. Cheerio
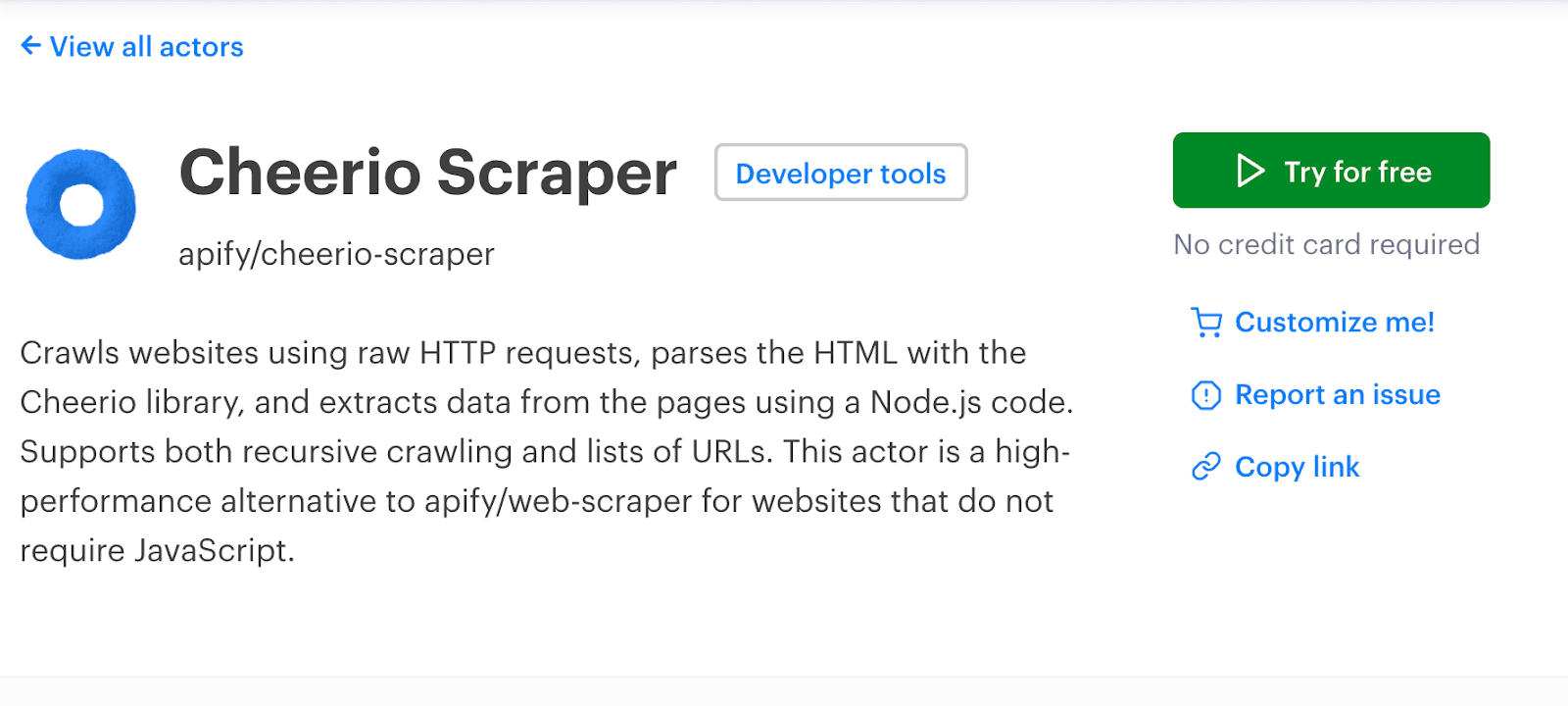
Cheerio is a fast, flexible, and lean implementation of core jQuery specifically designed for the server environment. Unlike Scrapy, which is a comprehensive web crawling and scraping framework suitable for a wide range of web scraping and data extraction tasks, Cheerio offers a more focused and lightweight approach.
It's particularly well-suited for developers who need to parse, manipulate, and render HTML on the server side without the overhead of a full web browser environment.
Cheerio provides a powerful and flexible API for extracting data from HTML documents. Developers can use CSS selectors to pinpoint the data they need, enabling precise and efficient data extraction tasks.
As user Nishant says on TrustPilot:
I’ve been using Cheerio AI for close to a year. My use case is for renewing SaaS subscriptions payment for my company and it’s worked well for me. My churn is lesser than before and my retention has gone up. The ability to send messages across 3+ channels helps me reduce my campaign spent by utilising cheaper channels like email and increase deliverability by using urgency channels like WhatsApp. The automation is great as well.
Which Alternative Will You Choose?
The best Scrappy alternatives come with their own unique features, capabilities, and of course different prices. Ultimately it boils down to which tool fits you and your team's need now and a year from now.
As a final bit of advice, if you're buying this tool for your team to use, make sure to include your team--you know, the people using the tool--in making the decision of which Scrappy alternative you'll choose. But if you want a scraping tool that's simple to use, requires no set up, and can scrape the info you need in a snap, choose Magical.
r the best scrapy alternatives? You've landed in the right spot. Diving into web scraping can feel like run through a maze blindfolded. But don't worry because we're here to make your journey smoother.
In this article, you'll learn about the best Scrapy alternatives that range from the straightforward task of HTML parsing to effortlessly navigating the complexities of dynamic web content. You'll also learn what features to look for in a Scrapy alternative.